12 minutes
Messaging Systems: Queues, Streams, and Exchanges
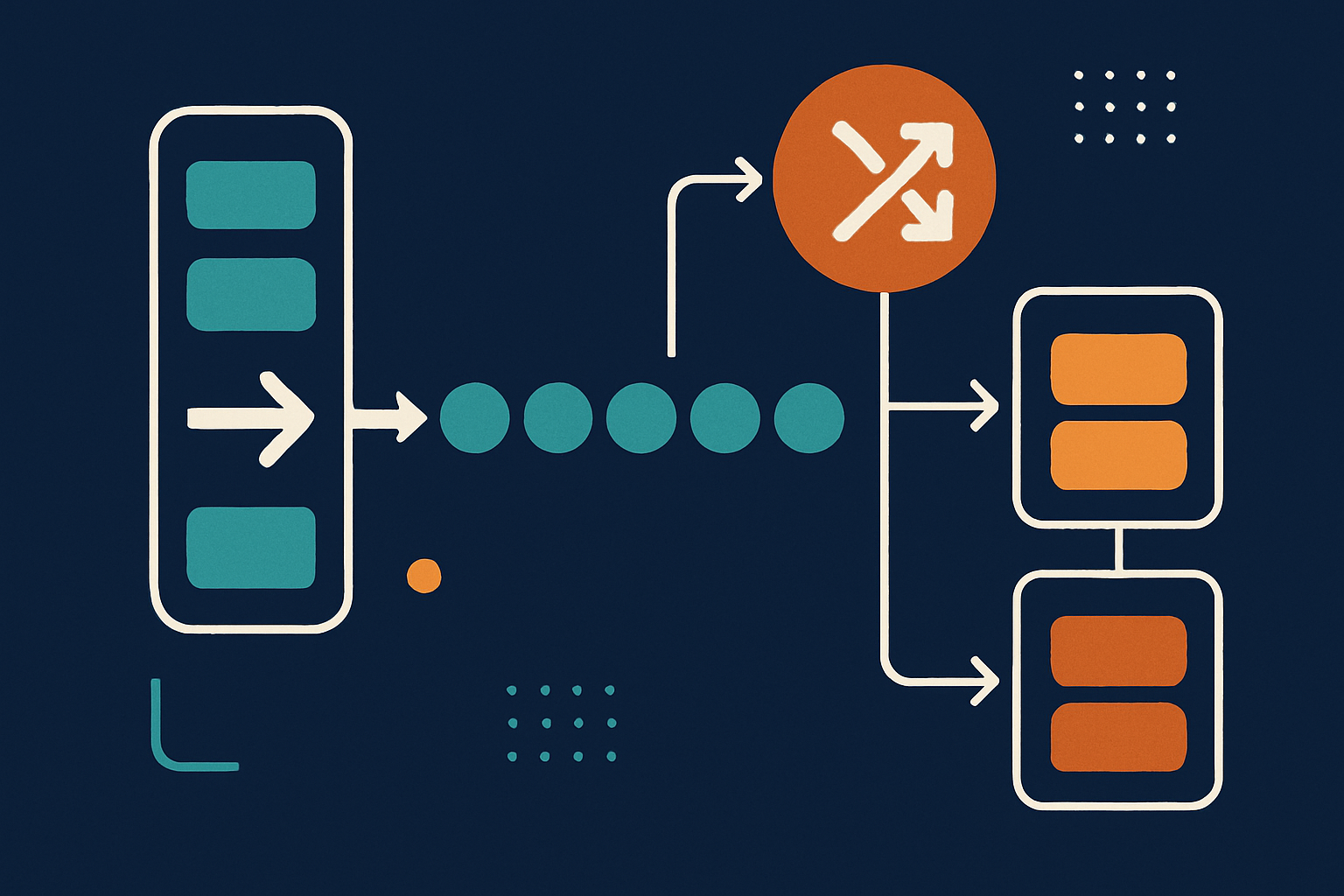
1. Introduction
Messaging systems are the backbone of modern distributed architectures, enabling reliable, decoupled, and scalable communication between services, applications, and devices. By passing messages asynchronously, these systems help manage complexity, improve resilience, and unlock new patterns for building robust cloud-native solutions.
Why use messaging systems? In today’s architectures, direct synchronous calls between services can lead to tight coupling, bottlenecks, and cascading failures. Messaging systems introduce a layer of indirection, allowing producers and consumers to operate independently, absorb spikes in load, and recover gracefully from failures. They also enable powerful patterns like event-driven processing, background jobs, and real-time analytics.
At their core, messaging systems revolve around a few key concepts:
- Producers: Components that send messages.
- Consumers: Components that receive and process messages.
- Messages: The data payloads being transferred.
- Topics/Queues: Logical channels for organizing messages.
- Partitions: Subdivisions for parallelism and scalability.
- Acknowledgments: Mechanisms to confirm successful processing.
Understanding these fundamentals is the first step toward designing resilient, scalable, and maintainable systems.
2. Messaging Paradigms: Core Types
Messaging systems come in several core paradigms, each with distinct characteristics and best-fit scenarios.
2.1 Message Queues (Point-to-Point)
Message queues deliver messages from a producer to a single consumer, following a point-to-point pattern. Examples include Amazon SQS, RabbitMQ, Azure Queue, and IBM MQ. These systems often guarantee FIFO (First-In-First-Out) delivery, though some may allow unordered processing for higher throughput.
Characteristics:
- One-to-one delivery: each message is consumed by only one consumer.
- Work dispatching: ideal for distributing tasks among workers.
- Supports load balancing and backpressure.
Pros:
- Simple to reason about.
- Decouples producers and consumers.
- Supports scaling consumers horizontally.
Cons:
- Not suitable for broadcasting the same message to multiple consumers.
- May require careful handling of message ordering and duplication.
When to use:
Use message queues for background job processing, task distribution, and scenarios where each message should be handled only once.
2.2 Event Streams (Distributed Logs)
Event streaming systems, such as Kafka, Kinesis, Pulsar, and Redpanda, use append-only logs to store and distribute messages. Multiple consumers can read from the same stream, and messages can be replayed as needed.
Characteristics:
- High throughput, append-only logs.
- Multiple consumers can read independently.
- Replayability: consumers can reprocess messages from any point.
Pros:
- Excellent for analytics, event sourcing, and audit trails.
- Scales to massive data volumes.
- Enables complex event processing and real-time pipelines.
Cons:
- More complex to operate and reason about.
- Requires careful partitioning and offset management.
When to use:
Choose event streams for analytics pipelines, real-time data processing, and scenarios where message replay or multiple consumers are needed.
2.3 Pub/Sub Systems
Publish/Subscribe (pub/sub) systems, such as Google Pub/Sub, Amazon SNS, Redis Pub/Sub, and NATS, allow messages to be broadcast to multiple subscribers.
Characteristics:
- Fan-out delivery: one message can reach many consumers.
- Loose coupling between producers and consumers.
- Often no message persistence (though some systems support it).
Pros:
- Great for notifications, real-time updates, and decoupling.
- Simple to add or remove consumers.
Cons:
- May not guarantee message delivery or ordering.
- Persistence and replayability are often limited.
When to use:
Use pub/sub for notifications, broadcasting events, and real-time updates to multiple consumers.
2.4 Task Queues / Job Queues
Task queues, such as Celery, Sidekiq, BullMQ, Hangfire, and RQ, are specialized for background job processing, retries, and scheduling.
Characteristics:
- Built on top of message queues.
- Support for retries, scheduling, and result tracking.
- Designed for background and batch processing.
Pros:
- Simplifies background job management.
- Handles retries and failures gracefully.
- Integrates with web frameworks and databases.
Cons:
- Adds operational complexity.
- May require additional infrastructure for result storage.
When to use:
Ideal for background jobs, scheduled tasks, and workflows that need retries or delayed execution.
2.5 Hybrid and Special Systems
Some systems blend multiple paradigms. For example, Apache Pulsar supports both streams and queues, RabbitMQ offers queue and pub/sub modes, and Redis Streams provides a hybrid log/queue model.
Choosing the right tool:
Evaluate your requirements for delivery guarantees, ordering, replayability, and scalability. Hybrid systems can offer flexibility but may introduce additional complexity.
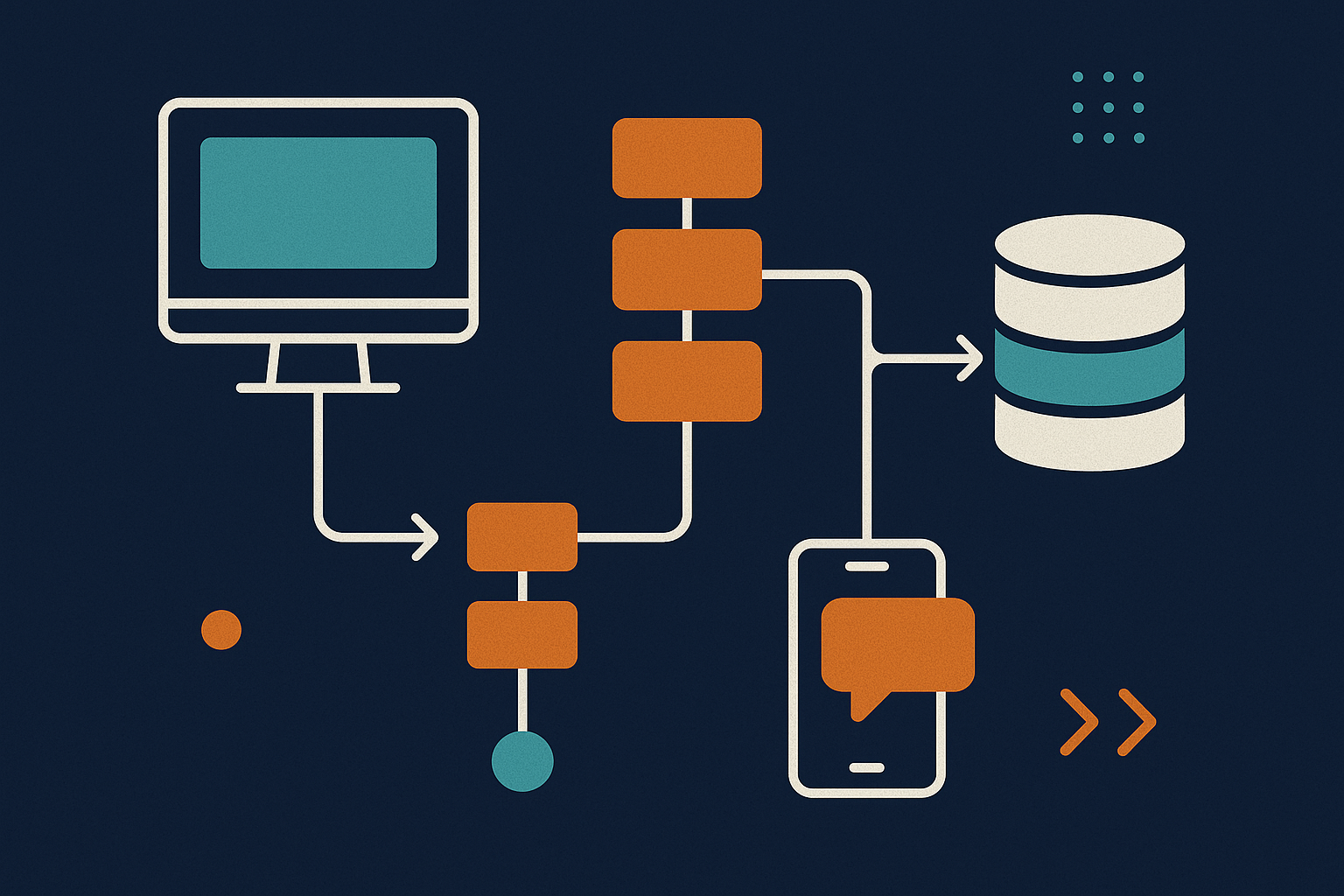
3. Common Use Cases
Messaging systems are used in a wide range of scenarios:
- Microservice communication: Decouple services and enable asynchronous workflows. For example, in an e-commerce platform, the order service can send a message to the inventory service to reserve stock, allowing both services to scale and fail independently.
- Background job execution: Offload heavy or slow tasks from user-facing services. For instance, a web app can enqueue image processing jobs to a task queue, letting users continue browsing while the images are processed in the background.
- Event-driven systems: React to changes and trigger workflows in real time. A payment gateway might publish a “payment received” event, which triggers notifications, shipment, and analytics services to act accordingly.
- Real-time analytics: Process and analyze data streams as they arrive. Online ad platforms use event streams to aggregate click and impression data in real time for dashboards and bidding algorithms.
- Log and telemetry pipelines: Collect, aggregate, and process logs and metrics. Cloud providers use event streaming systems like Kafka to ingest logs from thousands of servers, enabling centralized monitoring and alerting.
- Notification systems: Deliver alerts, emails, or push notifications. For example, a social network can use pub/sub to notify users instantly when they receive a new message or friend request.
- Video/image processing: Handle media uploads and processing asynchronously. Video platforms queue uploaded videos for transcoding, ensuring uploads are fast and processing happens reliably in the background.
- IoT pipelines: Ingest and process data from devices at scale. Smart home platforms use messaging systems to collect sensor data from millions of devices, process it in the cloud, and trigger automations or alerts.
4. Best Practices
Designing, operating, and scaling messaging systems requires careful attention to reliability, performance, and maintainability. Here are best practices for each stage:
4.1 Design
- Prefer “at least once” over “exactly once” for simplicity: Achieving true exactly-once delivery is complex and often unnecessary. Most real-world systems are built to tolerate duplicate messages, making “at least once” delivery a practical default. For example, payment processors use idempotency keys to ensure that even if a payment message is processed twice, the user is only charged once.
- Use message IDs or deduplication tokens: Assign unique IDs to each message so consumers can detect and ignore duplicates. Many cloud queues (like SQS FIFO) support deduplication out of the box.
- Keep messages idempotent: Design consumers so that processing the same message multiple times has the same effect as processing it once. This is crucial for reliability and simplifies error handling.
- Avoid tight coupling between producers and consumers: Use topics, queues, or exchanges to decouple services. This allows you to add, remove, or update consumers without impacting producers, and vice versa. For example, in a microservices architecture, the order service should not need to know about the inventory or shipping services directly.
4.2 Performance
- Use batching and compression: Sending messages in batches and compressing payloads can dramatically improve throughput and reduce costs, especially for high-volume systems like analytics pipelines.
- Monitor consumer lag / backlog: Track how far behind consumers are from the latest messages. High lag can indicate performance bottlenecks or under-provisioned consumers.
- Partitioning and sharding: Distribute messages across partitions or shards to enable parallel processing and scale horizontally. For example, Kafka topics can be partitioned by user ID to balance load.
- Use dead-letter queues for poison messages: Messages that repeatedly fail processing should be moved to a dead-letter queue (DLQ) for later inspection, preventing them from blocking the main queue.
4.3 Operations
- Monitor retries, DLQs, throughput, error rates: Set up dashboards and alerts to track key metrics. This helps you detect issues early and maintain system health.
- Set visibility timeouts and acknowledgment deadlines properly: Ensure that messages are not re-delivered too quickly or lost if a consumer crashes. For example, SQS uses visibility timeouts to temporarily hide messages while they are being processed.
- Don’t block consumers with heavy logic: Offload CPU-intensive or slow operations to background workers or separate services. Consumers should process messages quickly and acknowledge them to keep the system flowing smoothly.
5. Common Messaging Patterns
5.1 Work Queue Pattern
- Explanation: Distributes tasks among multiple consumers, ensuring each task is processed only once. This pattern is ideal for background job processing.
- Example: In an e-commerce platform, when a user uploads a product image, the image is placed on a work queue. Multiple worker services pick up images from the queue and process them (resize, compress, store), ensuring fast and scalable handling.
5.2 Fan-out / Broadcast Pattern
- Explanation: A single message is delivered to multiple consumers. This is the core of pub/sub systems, enabling real-time updates and notifications.
- Example: A social media app publishes a new post event to a topic. All followers of the user are subscribed and receive the update instantly, triggering notifications or timeline updates in their apps.
5.3 Routing Pattern
- Explanation: Messages are routed to different consumers based on rules, such as topics or headers. This allows selective message delivery.
- Example: In a stock trading platform, price updates for different stocks are published to topics named after stock symbols. Consumers subscribe only to the stocks they care about, receiving relevant updates without being flooded by all market data.
5.4 Competing Consumers Pattern
- Explanation: Multiple consumers read from the same queue or partition, competing to process messages. This pattern increases throughput and provides fault tolerance.
- Example: A ride-sharing app uses a queue for incoming ride requests. Multiple backend workers compete to pick up and process requests, ensuring fast assignment and handling spikes in demand.
5.5 Dead-Letter Queue (DLQ) Pattern
- Explanation: Messages that cannot be processed (poison messages) are moved to a special queue for later inspection, preventing them from blocking the main queue.
- Example: In a payment processing system, if a transaction message fails validation multiple times, it is sent to a DLQ. Operations teams can later review and resolve these problematic messages without affecting normal processing.
5.6 Retry with Backoff Pattern
- Explanation: Failed messages are retried after increasing delays, preventing system overload and giving time for transient issues to resolve.
- Example: An email service tries to send an email. If the SMTP server is temporarily unavailable, the message is retried after 1 minute, then 5 minutes, then 15 minutes, etc., until it succeeds or is sent to a DLQ.
5.7 Request-Reply Pattern
- Explanation: Enables RPC-like communication over asynchronous messaging, where a consumer processes a request and sends a reply message back to the producer.
- Example: A microservice requests a currency conversion from another service by sending a message with a reply-to address. The conversion service processes the request and sends the result back to the specified reply queue, enabling asynchronous yet direct communication.

6. Common Problems & How to Solve Them
6.1 Message Duplication
- Problem: Messages may be delivered more than once due to at-least-once delivery guarantees or network retries.
- Solution: Design consumers to be idempotent—processing the same message multiple times should have the same effect as processing it once. Use unique message IDs and track processed messages if necessary.
- Example: In a billing system, ensure that charging a customer for an order is idempotent by checking if the order has already been billed before processing the message.
6.2 Message Loss
- Problem: Messages can be lost due to broker crashes, misconfiguration, or network issues.
- Solution: Use persistent storage for queues/topics, enable message acknowledgments, and monitor broker health. Implement dead-letter queues for unprocessable messages.
- Example: In a logistics platform, enable message persistence in RabbitMQ and configure acknowledgments to ensure that shipment updates are never lost.
6.3 Ordering Guarantees
- Problem: Some systems require strict message ordering, but distributed systems can make this difficult.
- Solution: Use partitioning or sharding strategies that preserve order within a key or topic. Choose brokers (like Kafka) that support ordered delivery within partitions.
- Example: In a stock trading system, ensure all trades for a given account are routed to the same partition to maintain order.
6.4 Back Pressure & Overload
- Problem: Consumers may be overwhelmed by high message rates, leading to slow processing or crashes.
- Solution: Implement rate limiting, consumer scaling, and back-pressure mechanisms. Use message time-to-live (TTL) to discard stale messages if appropriate.
- Example: In a video processing pipeline, auto-scale worker pods based on queue length and set a TTL for video processing requests to avoid backlog.
6.5 Poison Messages
- Problem: Malformed or problematic messages can repeatedly fail processing, blocking the queue.
- Solution: Use dead-letter queues to isolate and inspect poison messages. Set a maximum retry count before moving messages to the DLQ.
- Example: In a payment gateway, if a transaction message fails validation three times, it is sent to a DLQ for manual review.
6.6 Security & Data Privacy
- Problem: Sensitive data in messages can be intercepted or leaked.
- Solution: Use encryption in transit (TLS) and at rest. Implement authentication and authorization for producers and consumers.
- Example: In a healthcare application, encrypt all patient data in messages and require OAuth2 authentication for all services accessing the message broker.
6.7 Monitoring & Troubleshooting
- Problem: Lack of visibility into message flows and broker health can lead to undetected issues.
- Solution: Implement comprehensive monitoring, logging, and alerting for brokers, queues, and consumers. Use tracing tools to follow message paths.
- Example: In a microservices platform, use Prometheus and Grafana to monitor queue lengths, consumer lag, and broker uptime, and set up alerts for anomalies.
7. Comparison Matrix: Popular Messaging Systems
| Feature / System | Apache Kafka | RabbitMQ | AWS SQS | Google Pub/Sub | NATS |
|---|---|---|---|---|---|
| Type | Log-based, Pub/Sub | Queue, Pub/Sub | Queue (Cloud) | Pub/Sub (Cloud) | Pub/Sub, Queue |
| Delivery | At least once, exactly once (with config) | At least once, best effort | At least once, best effort | At least once, best effort | At most once, at least once |
| Ordering | Per partition | Per queue | No (FIFO available) | No (ordering keys) | No (JetStream: yes) |
| Persistence | Durable, disk-based | Durable, memory/disk | Yes (cloud managed) | Yes (cloud managed) | Optional (JetStream) |
| Throughput | Very high | High | High | High | Very high |
| Latency | Low | Low | Low | Low | Ultra low |
| Scalability | Horizontal, partitions | Clustering, federation | Cloud auto-scaling | Cloud auto-scaling | Clustering |
| Protocol | TCP, custom | AMQP, MQTT, STOMP | HTTP(S), AWS SDK | HTTP(S), gRPC | TCP, WebSocket |
| Use Cases | Event sourcing, analytics, log aggregation | Task queues, pub/sub, RPC | Decoupling microservices, background jobs | Event ingestion, analytics | IoT, microservices, edge |
| Cloud Native | Self-managed, Confluent Cloud | Self-managed, CloudAMQP | Fully managed | Fully managed | Self-managed, NATS.io Cloud |
| Ecosystem | Rich, connectors | Plugins, management | AWS ecosystem | GCP ecosystem | Lightweight, simple |
Notes:
- Choose based on your needs: Kafka for high-throughput event streaming, RabbitMQ for flexible routing and protocols, SQS/PubSub for managed cloud simplicity, NATS for ultra-low latency and lightweight deployments.
- Consider operational complexity, cost, and integration with your stack.
8. Conclusion
Messaging systems are foundational to cloud-native architectures, enabling scalable, resilient, and decoupled communication between services. By understanding the core paradigms, use cases, patterns, and best practices, architects and engineers can design robust systems that handle real-world demands. Choosing the right messaging technology depends on your application’s requirements for throughput, latency, ordering, and operational complexity.
As cloud-native ecosystems evolve, messaging systems continue to play a critical role in event-driven design, microservices, and distributed data processing. By proactively addressing common challenges and leveraging proven patterns, teams can build reliable, maintainable, and future-proof solutions.
Whether you are building a simple task queue or a complex event streaming platform, a solid grasp of messaging fundamentals will empower you to make informed decisions and deliver value at scale.